
データの特徴を知るためには、合計や平均を計算することがあります。
この記事では、pandas の groupby や agg を使った集計方法を身に着けられます。
なお、本記事で使用する csv データは以下にあります。

データの概要
扱うデータは商品の売上の記録になります。
顧客ID,日付,カテゴリ,売上,担当者
00123,2024-01-05,食品,12000.0,田中
00456,2024-01-07,日用品,23309.090909090908,佐藤
00789,2024-01-10,食品,8500.0,田中
...読み込みこんだデータを groupby を使い、カテゴリで集計します。
df.groupby('カテゴリ').size()出力
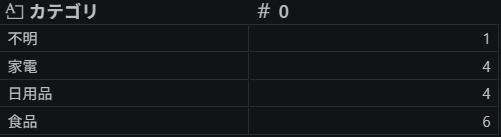
不明も含めてカテゴリは4種類あり、各カテゴリの行数もわかりました。
単純な集計:sum / mean
どのカテゴリが売れているか調べるために合計を計算してみます。
df.groupby('カテゴリ')['売上'].sum()出力
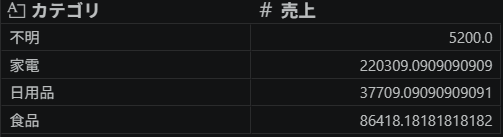
家電や食品の売上が大きいことが分かりました。この様に groupby('列名')['集計したい列'].集計関数() で集計できます。
同じように、カテゴリごとの売上の平均値を計算してみます。
df.groupby('カテゴリ')['売上'].mean()出力
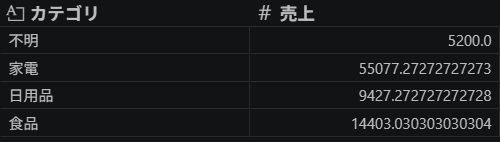
合計と同じく平均も家電や食品が高いことが分かりました。
複数列でグループ化する
さらに担当者別で集計をすることで細かく分析することが出来ます。
df.groupby(['カテゴリ', '担当者'])['売上'].sum()出力

家電は佐藤さんや田中さんの売上が大きいようですね。
複数の指標を同時に集計する:agg
sum と mean を別々に書くのは手間です。agg を使えば一度にまとめて計算できます。
df.groupby('カテゴリ').agg(
売上合計=('売上', 'sum'),
売上平均=('売上', 'mean'),
件数=('売上', 'count'),
)出力
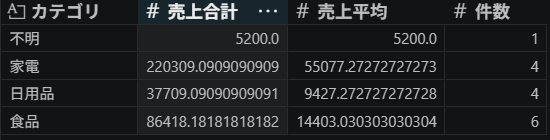
agg の辞書形式 新しい列名=('元の列', '集計関数') が最もよく使うパターンです。
まとめ
この記事では pandas を使って集計をしました。
import pandas as pd
df = pd.read_csv('cleaned_data.csv') # データの読み込み
# 集計
df.groupby('カテゴリ').agg(
売上合計=('売上', 'sum'),
売上平均=('売上', 'mean'),
件数=('売上', 'count'),
)
コメント